There's a problem that anyone who works in scholarly publishing knows intimately, but rarely says out loud: a substantial portion of what lands in an editor's inbox shouldn't be there. Not because the research is controversial, or the methodology is unconventional, but because it simply doesn't meet the bar. A trained eye can tell within minutes.
The question is: whose minutes?
Submission volumes across scholarly journals have increased significantly in recent years, and the editorial infrastructure that supports peer review hasn't kept pace. Many teams still operate on a "light touch" triage model, desk rejecting precious few manuscripts, and sending the rest out for review on the assumption that the system can absorb it. (For a while, it could!)
But as submission volumes have surged, that assumption has started to break down. Reviewer communities can only sustain so much. When scarce expert attention is routinely directed at manuscripts with little realistic chance of acceptance, it erodes the capacity of the whole system over time.
The automated screening tools that have emerged in response do important work. But very often they're catching bad actors, not bad science. They flag the fraudulent; they don't evaluate the flawed. That's a different problem.
What It Actually Means to Assess a Manuscript
Evaluating whether a piece of research deserves peer review isn't just about catching obvious problems. It requires reading the work, understanding its claims, and making a judgment across several dimensions: Is this genuinely new? Does it belong in this journal? Is the methodology sound? Does it add something to the field?
For a long time, the assumption has been that this kind of assessment is irreducibly human. It requires domain expertise, nuanced judgment, and the kind of contextual knowledge that can't be systematized. Whilst this is still the case, AI is starting to gain ground and can play an important role in the assessment process.
Hum's Alchemist Review was built to do exactly this: content-level assessment of manuscripts, operating securely across four dimensions - novelty, journal scope match, scientific rigor, and significance.
Not keyword matching. Not surface-level screening. Evaluation of the research itself.
What the Data Shows
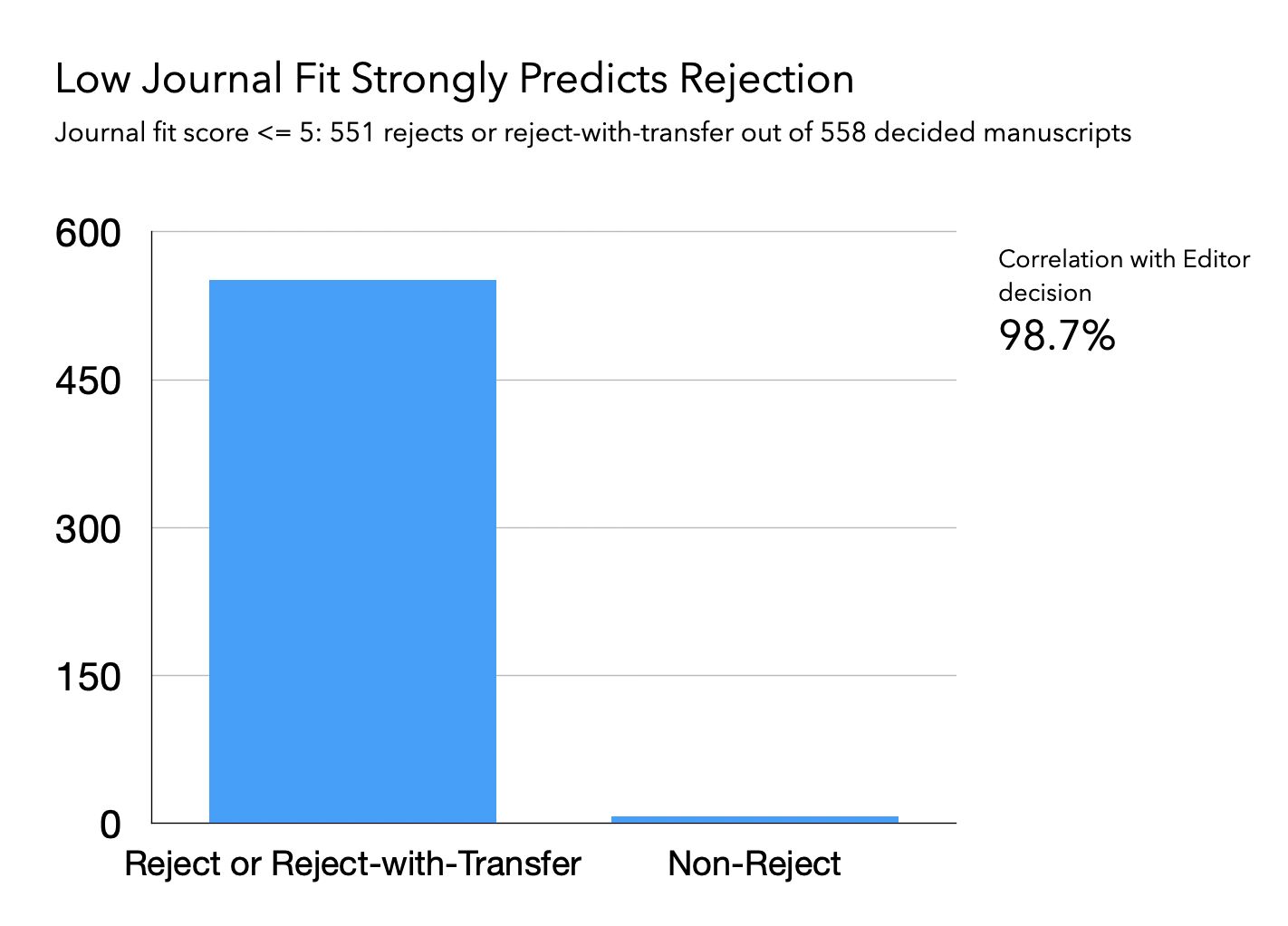
We recently ran 558 submitted manuscripts through Alchemist Review and tracked the first editorial decision for each. The results were striking.
For manuscripts that scored poorly — below 5 on a 10-point scale — there was a 98.7% correlation with the editor's decision to reject or redirect the paper.
It's worth being precise about what this means, and what it doesn't. This isn't a claim that AI has replaced human editorial judgment. A domain expert still confirms the decision. The research still gets a trained eye on it before anything moves forward.
What it shows is that when Alchemist Review flags a manuscript as a poor fit, it is almost never wrong. The low-score bucket is highly concentrated with eventual rejects. Obvious cases can be closed quickly, and the time saved is real.
Addressing a Reasonable Question
Some will ask: is agreement with editorial outcomes really the right benchmark?
Editorial decisions, after all, involve judgments about journal fit, readership interest, and strategic scope; not only scientific validity in the abstract.
That's a fair point, and it's also exactly the point.
Editors aren't making decisions in a vacuum. They're evaluating whether a manuscript belongs in their specific journal, at this moment, for their readers. Alchemist Review is trained to evaluate manuscripts along those same dimensions. When the two align at 98.7%, it's not a coincidence. It's evidence that the system is assessing what editors actually care about.
The goal here isn't to ask whether Alchemist Review can perfectly replicate the full depth of human scientific judgment. The goal is more targeted: can it reliably identify manuscripts that aren't going to make it — before an editor spends an hour with them, before they're sent out to reviewers, before they consume time that could be spent on work that actually has a chance?
On that narrower question, the answer increasingly appears to be yes.
What Gets Unlocked
There's an asymmetry in editorial work that often goes unacknowledged. The manuscripts that deserve serious attention — ones that are close to the line, the ones with genuine novelty and real methodological questions — are exactly the ones where editor and reviewer time is most valuable. These are the papers where a careful read changes outcomes. Where pushing back on a methodology section, or asking for a revision, makes the final published work meaningfully better.
That work suffers when the same attention is given to manuscripts that had no realistic path to acceptance. Not because editors lack diligence, but because time and reviewer goodwill are both finite, and burning either on low-likelihood manuscripts is a cost the system increasingly can't afford.
When deep analysis is available before an editor even opens a manuscript, the dynamic shifts. Clear cases can be closed quickly, and editors can reserve their full attention for the ambiguous, consequential decisions that actually require it.
Learn more about Alchemist Review - or see how it works on your manuscripts.
We'll run 50 manuscripts free through Alchemist Review and return a full results summary: fit scores, integrity flags, desk-reject recommendations, & methodology assessments for every paper